We just replaced the initial Tax related databases and got rid of the _NEW tag that was appended to the name. To learn about the content please reads this (or this) from our knowledge base.
Manish has been working diligently to update these and I think he has done a tremendous job even though sometimes from the outside it might look like we are not making progress. We now have data from 2015 filings available in the TAX_RECON file. The DEFERRED_TAX file is still limited to filings back to 2019. For both files we are adding data as it is filed with EDGAR weekly.
Remember – we are trying to merge the XBRL data with the data that was originally reported in the HTML table in the 10-K/EX-13s. When we conceived of this as a way to add more robustness and utility to the data that exists in the ExtractionPreprocessed system as we move it to the database it seemed like an easy proposition. Unfortunately that has not been the case. Frankly all of our work makes us very suspicious of any data pulled directly from the XBRL as it is just not very complete and or has other issues.
I am going to try to document some of these issues in a later post.
We are in the midst of doing some rationalization of our databases. All the changes will be reported in Knowledge Base in the section that describes the databases and their fields. Our goal is to bring some more discipline to our field names and the organization of the databases. Most of the changes will be minor (for example every table that has a field CIK_ACCESSION that field will be renamed to CIK_ACC. We have some tables that have ACCESSION_NUMBER others that have ACCESSION. All of those will be standardized to ACCESSION. There are two reasons for these changes. First, we are working on an update to the Extraction Engine – one of the features is that we want is to dynamically accept fields to filter on that come from a CSV file. Right now the only field you can filter on using a CSV file is CIK, but at some point we want you to be able to filter on any field based on the contents of a file that has the criteria. To make this work we need to be more disciplined with the names we assign to fields.
Another change is that all ACCEPTANCE_DATETIME fields in all databases are going to be converted to ISO 8601 format (YYYY-MM-DDTHH:MM:SS). Currently the fields are stored as reported in the header file YYYYMMDDHHMMSS. But that format is not really easy to work with – especially for a novice as I discovered today.
I am trying to coach my interns on using ChatGPT to develop more content and skills and so in preparation for one of my ideas about coaching them I decided to prepare to help them through creating Python code to select all 8-K filings made after 4:00 PM on Fridays. This is a project that some of our clients have used in their classrooms in the past and I wanted to approach it as a interested novice. However, as I was working through the process the query to select – especially the after 4:00 PM constraint got more and more complex. I finally wondered if it would be simpler if the field value was changed. To test this I created another copy of the db and changed the field. The resulting query was so much simpler after that change. So, if you can imagine that you wanted to replicate this – here is the exchange I had with ChatGPT after the modification (note the platform database has been modified as of now):
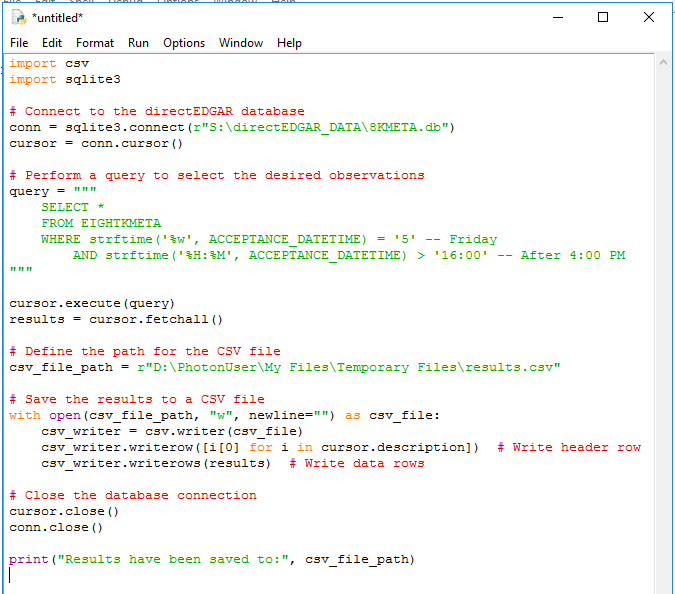
I have a database that is at S:\directEDGAR_DATA\8KMETA.db there is one table named EIGHTKMETA the primary key is CIK_ACC there is a field named ACCEPTANCE_DATETIME – here is a sample value from that field 2022-12-16T08:19:33 is there a way to write Python code to select all observations where the ACCEPTANCE_DATETIME is after 4:00 pm on Fridays. I want to save the results in a csv file and the directory where the results should be saved is “D:\PhotonUser\My Files\Temporary Files\”
Here is the code – and guess what – it worked – but let’s walk through the process of getting it on the platform and ready to run.
import sqlite3
# Connect to the database
conn = sqlite3.connect(r"S:\directEDGAR_DATA\8KMETA.db")
cursor = conn.cursor()
# Select all observations where ACCEPTANCE_DATETIME is after 4:00 pm on Fridays
query = """
SELECT *
FROM EIGHTKMETA
WHERE strftime('%w', ACCEPTANCE_DATETIME) = '5' -- Friday
AND strftime('%H:%M', ACCEPTANCE_DATETIME) > '16:00' -- After 4:00 pm
"""
cursor.execute(query)
results = cursor.fetchall()
# Process the results
for row in results:
# Access row data using row[index]
# ...
# Close the database connection
cursor.close()
conn.close()
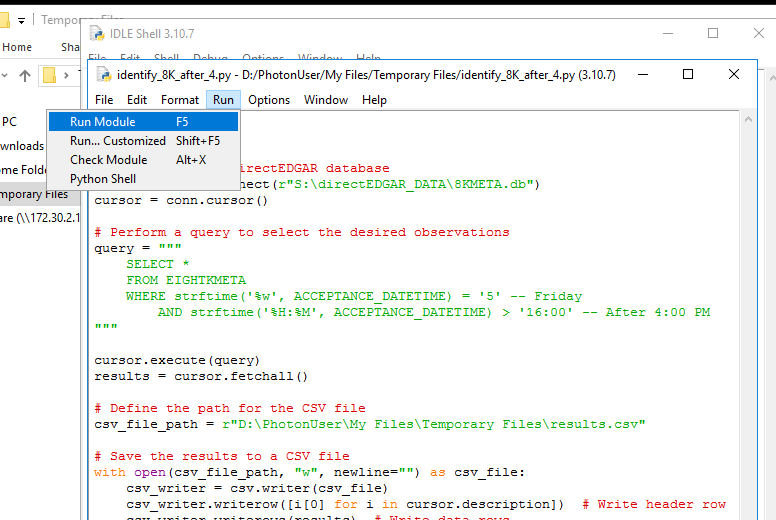
To use this code we need to get it up to the platform – assuming I am already in a session – I just need to open IDLE – the most direct way is to use the tiles on the browser frame.
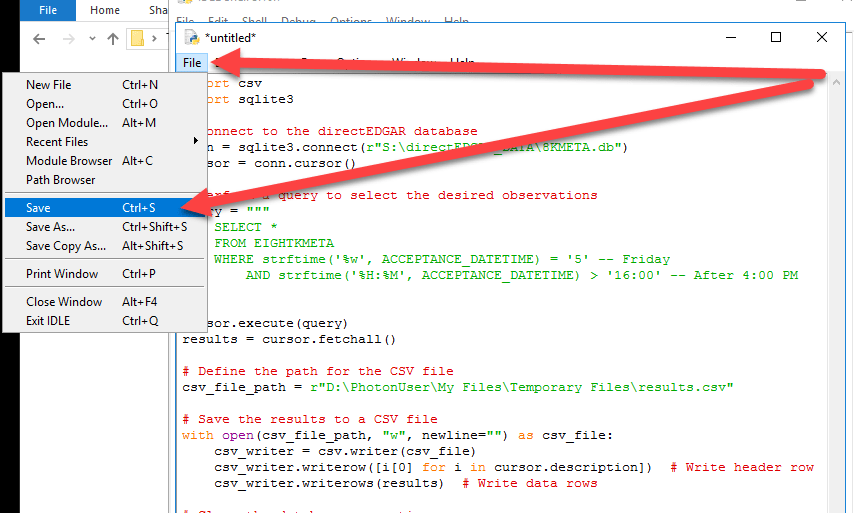
I need to open a New File so I can save the code and use or modify as needed. From the File menu in IDLE select New File.
Presumably I am working with ChatGPT on my local computer and the code was generated in a session so I need to transfer the code to the New File I opened – so using the Copy Code feature provided by ChatGPT copy the code to the clipboard.
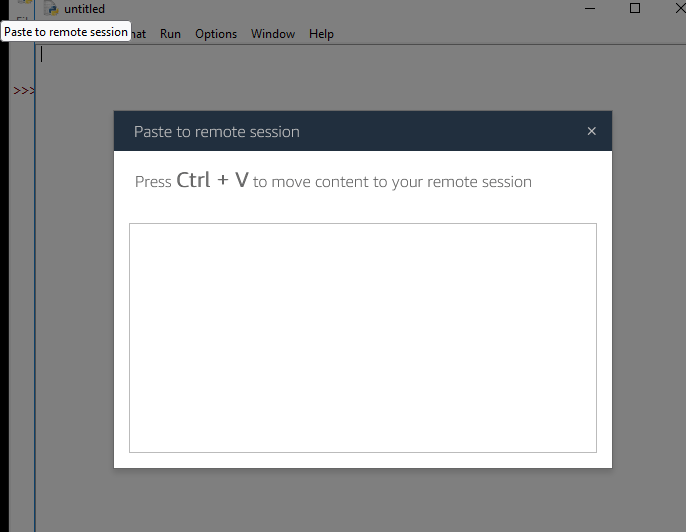
To transfer the contents of the clipboard to the remote session use the control in the browser frame (a fuller description can be found in the Knowledge Base here) to select Paste to Remote Session and follow the prompt to paste into the container that appears.
After hitting Ctrl+V you should see your content pasted into the container and the container will close. Put your mouse in the top right corner of the file you opened from within IDLE and hit CTRL+Vagain to then paste the code into IDLE.
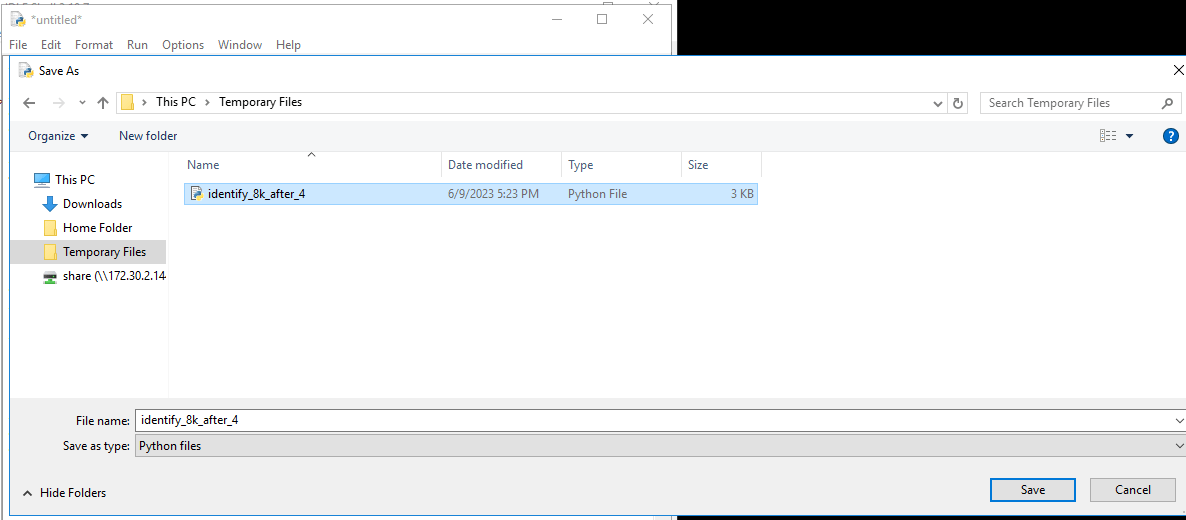
Before we can run this we need to save the code – while you have a home folder, presumably you are like me and what to keep things close and safe so I am going to save to the Temporary Files folder and then move it to my local computer when I am finished.
In this case I have saved the file with the name identify_8k_after_4.py.
Now I am ready to run this file – To run, select Run Module from the Run menu.
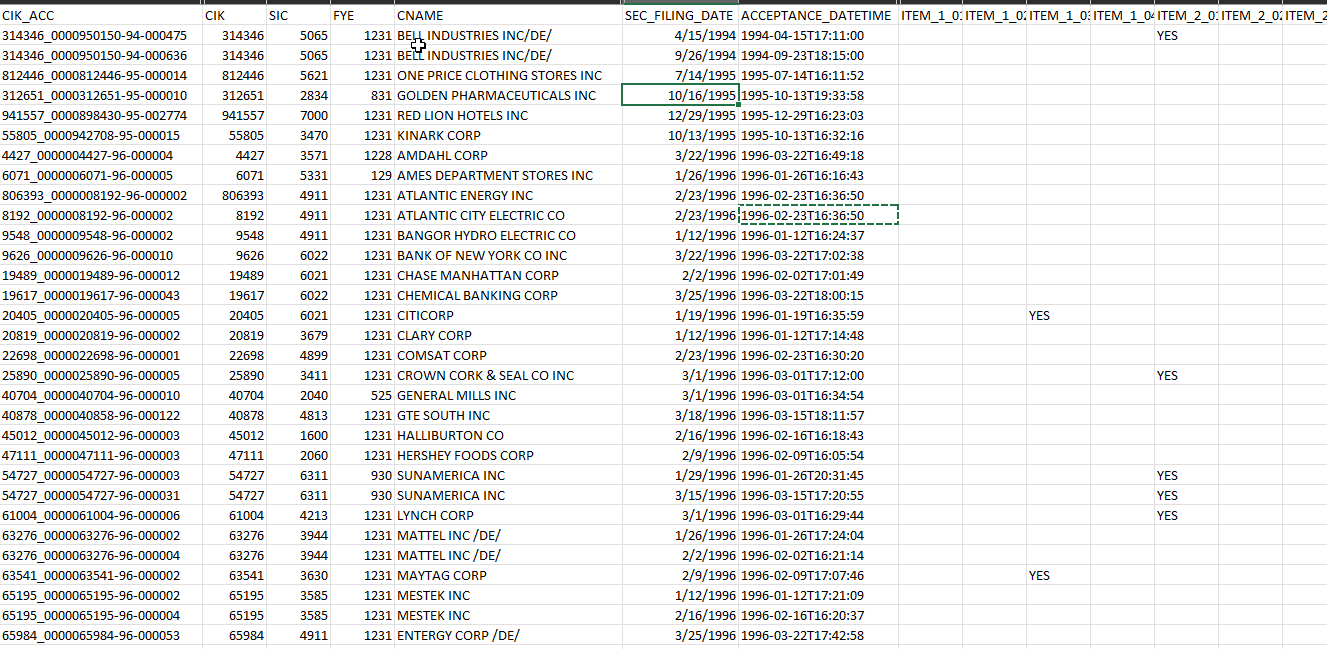
It took about a minute to run this code and generate the results. A screenshot does not give the result file enough justice as their are too many fields. I have hidden some to make the results a bit clearer. If you are a real SEC guru and are wondering why we have those particular ITEM codes – we recoded all earlier 8-K item codes to match the current ones adopted after SOX.
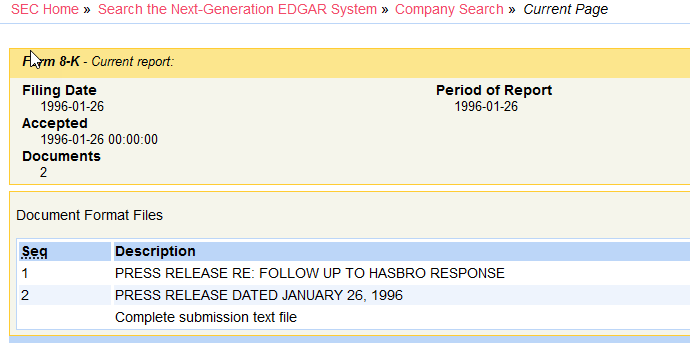
Forgive me for bragging – notice that we have the time listed in those early filings – most cannot be found in the header file. For example, notice the 8-K filing for Mattel on 2/26/1996. The header file reports time of midnight:
In these cases, if we could find a dissemination time – we replaced the header ACCEPTANCE_DATETIME with the dissemination time.
Remember – to transfer the results file (and probably the code file) back to your local computer follow the steps outlined here. Note – the 8KMETA.db now has the field ACCEPTANCE_DATETIME in the ISO 8601 format. Others will follow soon.