Lookie here – all of this metadata to be available on directEDGAR beginning on 8/30/2021:
<meta name="SICODE" content="7370">
<meta name="FYEND" content="1231">
<meta name="CNAME" content="ALPHABET INC.">
<meta name="FILINGDATE" content="20200204">
<meta name="ACCEPTANCE" content="20200203210359">
<meta name="ZIP" content="94043">
<meta name="DOCTYPE" content="10K">
<meta name="SECPATH" content="https://www.sec.gov/Archives/edgar/data/1652044/000165204420000008/goog10-k2019.htm">
<meta name="AddressCityOrTown content="MOUNTAIN VIEW">
<meta name="CurrentReportingStatus content="YES">
<meta name="SmallBusiness content="FALSE">
<meta name="WellKnownSeasonedIssuer content="YES">
<meta name="EmergingGrowthCompany content="FALSE">
<meta name="FilerCategory content="LAF">
<meta name="ShellCompany content="FALSE">
<meta name="AddressStateOrProvince content="CA">
<meta name="VoluntaryFilers content="NO">
<meta name="PublicFloat" content="663000000000.0">
<meta name="FloatDate" content="2019-06-28">
<meta name="CommonStockSharesOutstanding_1" content="299895185">
<meta name="ShareDate" content="2020-01-27">
<meta name="SecurityName_1" content="CommonClassA">
<meta name="CommonStockSharesOutstanding_2" content="46411073">
<meta name="SecurityName_2" content="CommonClassB">
<meta name="CommonStockSharesOutstanding_3" content="340979832">
<meta name="SecurityName_3" content="CapitalClassC">
<meta name="AUDITOR" content="ERNST & YOUNG">
<meta name="REPORT_DATE" content="2/3/2020">
<meta name="LOCATION_CITY" content="SAN JOSE">
<meta name="LOCATION_STATE" content="CALIFORNIA">
<meta name="SINCE" content="1999">There is a lot of noise above (and I don’t think Jimmy Buffett is noise)- what is that? That is the new metadata block that was added to the 10-K Alphabet Inc. submitted to the SEC on 2/4/2020. This has taken longer than I had hoped – one of the reasons for the delay is the number of our clients who asked how to identify the auditor caused me to do some research. I learned that the availability of auditor data is spotty prior to the disclosure of audit fees beginning in 2001/2002. I know a number of our clients were using our search tools to find/identify the auditor and so that made me decide it was worth the effort to add the information we could about the auditor.
I think the most common request before this was either the accession number of the source file (accession.txt) or the path to the documents returned from a search. I will be happy to take feedback if you feel like the accession number should be added as a direct piece of metadata. However, as I think about balancing everything I have initially determined that since the accession number follows the CIK and is before the actual file name ( 000165204420000008 ) – it is easy enough to parse out of either a SummaryExtraction or ContextExtraction product created by the platform.
When available in a document, all of this metadata is accessible if you do a search and then do a SummaryExtraction of the results. Clearly some fields are not likely to be useful for searching, like (ACCEPTANCE). Some, though, are likely to be very useful for constructing your search – remember that disclosure requirements vary by FilerCategory. For instance, a LARGE ACCELERATED FILER (LAF) has an accelerated filing schedule relative to other filers (10-K is due 15 days sooner than a 10-K for an Accelerated Filer) and carries the largest disclosure burden of all filers.
To access the new fields, press the “fields” button. The Select Field box will become available, which allows you to populate the Value field in the interface. While you can use as many fields as you’d like in a search, you have to add them one at a time. This image shows the Select Field tool for the new Y2016-Y2020 index:
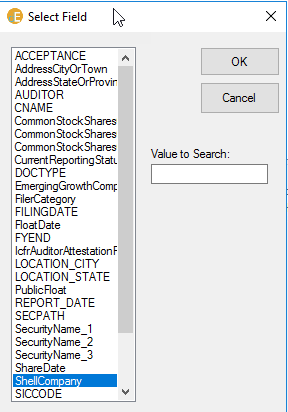
The case of the listed fields is an indicator of the source of the field. If the field name is all upper case – we generated the value from some artifact during the processing or outside the system. If the field name is a sequence of words with the first letter in each word capitalized – we captured the field value from the filing in more or less an automated process.
We are adding less metadata to the exhibits included with the 10-K. Basically, we will be leaving out everything after the SECPATH value. Here is the metadata that is going to be embedded in the first Exhibit 10 filed with the 10-K referenced above:
<meta name="SICODE" content="7370">
<meta name="FYEND" content="1231">
<meta name="CNAME" content="ALPHABET INC.">
<meta name="FILINGDATE" content="20200204">
<meta name="ACCEPTANCE" content="20200203210359">
<meta name="ZIP" content="94043">
<meta name="DOCTYPE" content="EX10">
<meta name="SECPATH" content="https://www.sec.gov/Archives/edgar/data/1652044/000165204420000008/googexhibit10081.htm">
One of the consequences of not including the full field set that is attached to the 10-K filing into the exhibits is that it is not yet possible to directly search for EXHIBIT 10s that were included in the 10-K filings of a LARGE ACCELERATED FILER. Instead you would have to first run a search for (DOCTYPE contains(10K)) and (FilerCategory contains (LAF)). This will identify all 10-K filings made by LAFs. Do a summary extraction, save that file and pull the CIKs. Use that CIK list to do a CIK filtered search for (DOCTYPE contains(EX10)) and your search will only return EXHIBIT 10s that were included in a 10-K filing made by a LARGE ACCELERATED FILER.
The following table contains a list of the metadata labels as well as their definition. If you are a current filer you will receive an email that includes a third column (SOURCE) which describes how the value was determined.
| METALABEL | DEFINITION |
| SICCODE | Standard Industrial Classification Code (as assigned by the SIC) |
| FYEND | Fiscal Year End for the most recent balance sheet included in the 10-K |
| CNAME | Company Name |
| FILINGDATE | The date the filing was submitted to EDGAR |
| ACCEPTANCE | The date-time stamp associated with the acceptance of the filing by the EDGAR system |
| DOCTYPE | The registrant is required to classify each document in a filing – this tag indicates the classification of the document assigned by the registrant. |
| SECPATH | The full path to the filing on EDGAR |
| VoluntaryFilers | YES/NO to indicate if the registrant is making this filing on a voluntary basis. |
| SmallBusiness | TRUE/FALSE to indicate if the registrant meets the SEC definition of a Small Business Filer |
| ShellCompany | TRUE/FALSE to indicate if the registrant meets the SEC definition of a Shell Company |
| FilerCategory | The registrants conclusion regarding their classification per the SEC’s filer category classification definitions |
| FilerCategory | LAF – Large Accelerated Filer |
| FilerCategory | AF – Accelerated Filer |
| FilerCategory | NAF – Non-Accelerated Filer |
| FilerCategory | SRC – Smaller Reporting Company |
| FilerCategory | SRAF – Smaller Reporting Accelerated Filer (this is actually not a valid classification but it has been used by a number of registrants – there are 55 10Ks with this self-reported label) |
| EmergingGrowthCompany | TRUE/FALSE to indicate if the filer meets the definition of an emerging growth company |
| WellKnownSeasonedIssuer | YES/NO to indicate whether or not the filer meets the definition of a Well Known Seasoned Issuer |
| CurrentReportingStatus | Yes/No to indicate if the registrant is current on their mandated filing obligations |
| AddressStateOrProvince | The State or Province of the headquarters of the filer |
| AddressCityOrTown | The name of the City or Town of the headquarters of the filer |
| ZIP | The ZIP/POSTAL code component of the address of the filer |
| PublicFloat | The aggregate market value of the shares of the registrant held by non-affiliates as of the last day of the registrants most recent second quarter (if multiple float values are reported we sum them to maintain consistency – we do validation checks to catch the cases where a total is reported as well as the float for each class) |
| FloatDate | The date used to determine the public float |
| CommonStockSharesOutstanding_1 | The number of shares reported as outstanding – if there are multiple share types/classes reported this is the first listed. |
| ShareDate | The measurement date which is the latest practical date (closest to the filing date) of the 10-K |
| SecurityName_1 | If provided, the name of the security whose common shares outstanding are listed as CommonStockSharesOutstanding_1 |
| CommonStockSharesOutstanding_2 | The number of shares reported as outstanding – if there are multiple share types/classes reported this is the security listed second. |
| SecurityName_2 | If provided, the name of the security whose common shares outstanding are listed as CommonStockSharesOutstanding_2 |
| CommonStockSharesOutstanding_3 | The number of shares reported as outstanding – if there are multiple share types/classes reported this is the security listed second. |
| SecurityName_3 | If provided, the name of the security whose common shares outstanding are listed as CommonStockSharesOutstanding_2 |
| IcfrAuditorAttestationFlag | TRUE/FALSE to indicate whether the filing includes an attestation by the/an external auditor on the Internal Controls over Financial Reporting |
| AUDITOR | The name of the auditor of the most recent financial statements (conforming to the FYEND tag) |
| REPORT_DATE | The audit report date |
| LOCATION_CITY | The city location of the auditor |
| LOCATION_STATE | The state/country of the auditor. |
| SINCE | The tenure of the auditor |
This is only the beginning of our work on improving the opportunity to add fields to the filings. Right now the team has auditor details back to 2007 – we will collect all the way to 1994. We have identified a way to add an ACCEPTANCE datetime stamp to the earlier filings. While it is not available in the index or hdr files for most filings prior to about 2002 we have determined how to identify a very good proxy for this value. We will be redoing the 2021 10-K filings in the next week or so to add in the same meta data and then we will next redo the 2010 – 2015 10-K filings. We have also been working on supplementing the self-reported IcfrAuditorAttestationFlag field and are close to being able to add this value to a significant number of filings.
Details matter a lot. We have standardized the auditor names but we have not yet made any attempt to roll back auditor name changes. We cannot consider doing this until all of the auditor data has been collected. If you are an existing client and need the mappings for the auditor name standardization send me an email. We will not be fully populating all of the SINCE fields until all of the auditor data has been collected. We tried to use some algorithms to add this value when it was not reported but we were not happy with the results. Specifically there are too many cases of auditors reporting this value as the year they signed an engagement letter with the registrant – not the first year they audited financial statements.
Another Details matter a lot point – there are some registrants that report more than three classes of stock. There was one who reported nine values for CommonStockSharesOutstanding (indicating 9 classes of securities). But when we analyzed these we discovered that once we moved past 3 the results were fairly dicey with respect to trying to use the reported values in a meaningful way. If you are interested – we identified 41 unique CIKs that reported more than 3 classes of securities. Here is a link to the interactive data presentation for one (Strategic Student Housing & Senior Trust Inc). The only registrant I could identify where I thought this value was useful was Molson Coors (great product!) but in weighing where to start and recognizing that we would be adding two additional columns that would only be meaningful for one CIK – that seemed to be too much. We can revisit this based on your feedback.
We are doing something else that is pretty cool but I think I need to keep it under my hat for the moment. I just don’t want you to think this is it. There is always more!
As an aside one of the things I would still like to do is to push all of this field data into a database – make an isolated copy of the database and then provide you with the tools to access it for a data analytics class. I look at some of the stuff that is being used and I wonder whether or not those databases give students a real sense of the complexity and ‘messiness’ of real data. For example – there is no category SMALLER REPORTING ACCELERATED FILER – we only learn it exists by testing the data and establishing that some filings did not have a valid value for Filer Category. I could imagine creating a database that combines this metadata with other data (such as compensation) to give students a richer experience working with real financial data. Poke me if this interests you.
I will send a direct email to you as soon as this is complete. As of 5:45 PM 8/28 – this is the current status of the indexing operation: