I have wanted for some time to provide you the ability to use Python to interact with our repository. It is complicated and a bit frustrating as the documentation from AWS is not material I easily consume (read understand) and there are the significant restrictions on the rights associated/provided to the user profile. However, interacting with some of our clients over the last several weeks forced me to realize that we could lessen their burden a decent amount if they could interact with our archive and databases using Python in addition to our search interface. Unfortunately I am still struggling to keep the Idle shortcut on the Windows Desktop – I ultimately decided that since my clients are some of the smartest people in the world you would not mind using the Windows menu system. Below is an image where I am in a session similar to the one you would be in and am starting Python Idle.
If you by chance find the Window’s tile icon unresponsive (as I did when sharing this with my team hours after the original publication) there is another way to easily access Idle. In the top left corner of the browser frame that contains your session are a number of icons – the left-most icon is a one-dimensional set of tiles – don’t click on it – move your mouse on top of it and the applications we have made available for your use will be listed.

We will slowly add some code examples – but I suspect many of you have more skills than I do. When we add a code example it will be in S:\PythonCode. You have read privileges on S: but not write privileges.
If we provide Python code then we will try to comment carefully where you may need to modify the code. In this example, I was responding to a user who had a question about the raw 13F data so I ran a test to pull data for 6 years conditioned on a list of CIKs. For you to run this code you would need to have your own list of CIKs and specify your own destination. If you make the changes you would have to save the file – but you can’t save on S you would be best served by saving in Temporary Files and downloading and saving it for your own future use.
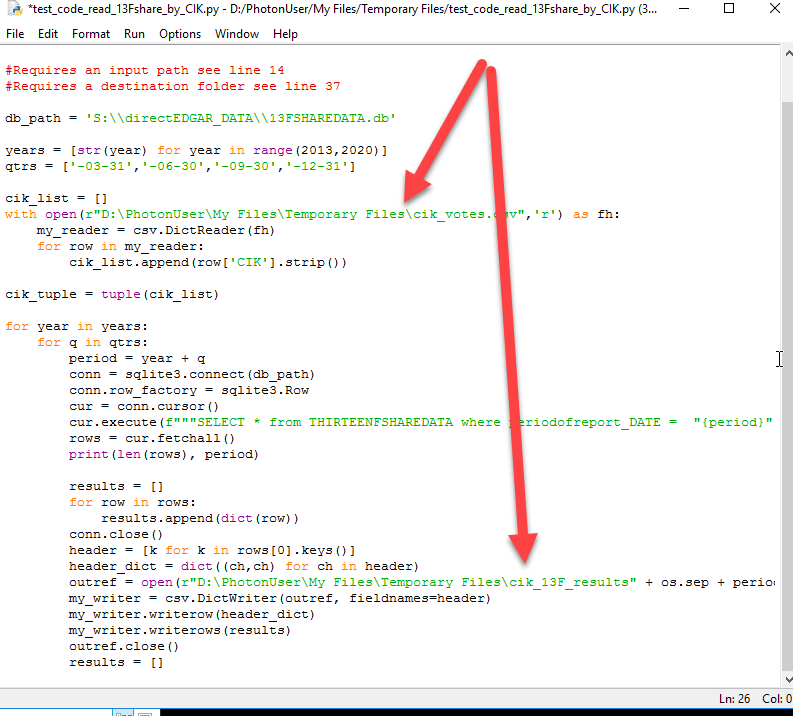
To be clear, I have specified an input file in that code that is a CSV file with a column named CIK and I have an output folder specified that is named cik_13F_results. If you want to run this code, you will need to upload a file with a column labeled CIK and you will have to create a directory and make the changes to the code. Note – in Appstream you are the PhotonUser.
I will say that running a query using Python is faster and less resource intensive than using our Query tool because we can use a loop to break down the SELECT statement. It took about 10 minutes to generate the the six years of quarterly output files.
I did reach out to Antonis Kartapanis (TAMU) and asked him what libraries he would like available. He suggested Pandas, Numpy and BeautifulSoup4. Those are available. And since we have a long history of using LXML – that is also available. You are not able to install any preferred libraries on your instance. However, we will update these with new tools as you communicate your needs to us.
I suspect one or more of you might groan – Idle. The problem with providing access to PyCharm is that it is a licensed product and we just can’t afford to meet their very reasonable license fee requirements (there is no sarcasm in that statement – their fees are very reasonable). We are investigating allowing you to bring your license but there are only 24 hours in a day! In the meantime you can work on your code locally using PyCharm (or your preferred editor) with one or ten files of the type you will be working with and then when finished to your satisfaction move it up and run it there. It is not perfect – but better than yesterday where you would have had to download the filings you wanted to work with.
Over the coming weekend I will provide some guidance on how to use search results from our Amazing and Best in Class Search SEC Filing Search Tool with Python to accelerate your data collection.













































